Imagine-2-Drive Architecture
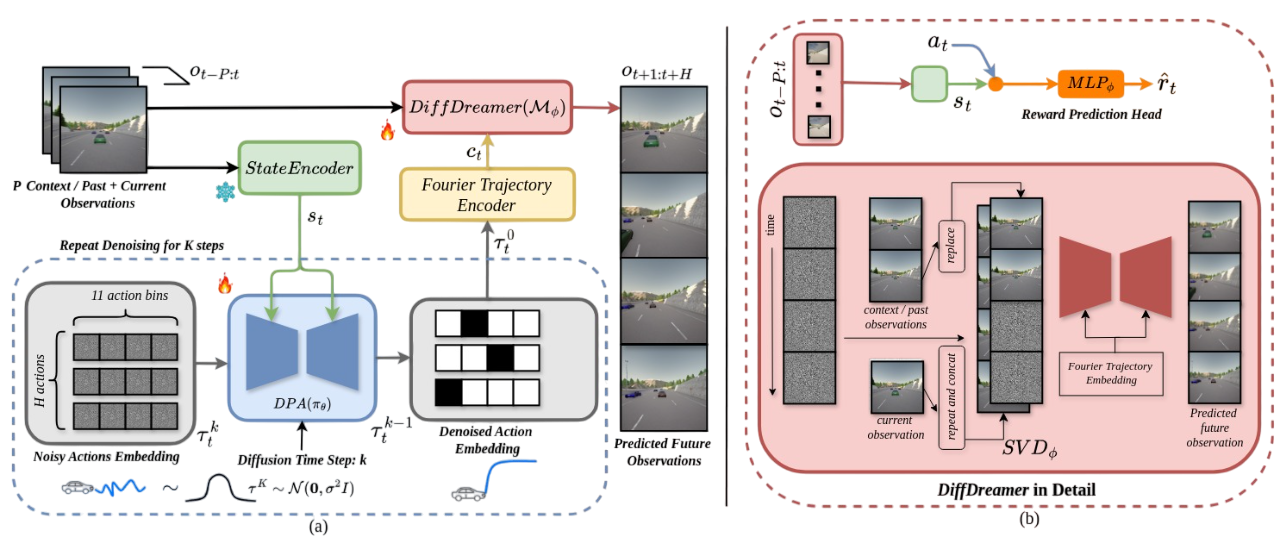
World Model-based Reinforcement Learning (WMRL) enables sample efficient policy learning by reducing the need for online interactions which can potentially be costly and unsafe, especially for autonomous driving. However, existing world models often suffer from low prediction fidelity and compounding one-step errors, leading to policy degradation over long horizons. Additionally, traditional RL policies, often deterministic or single Gaussian-based, fail to capture the multi-modal nature of decision-making in complex driving scenarios. To address these challenges, we propose Imagine-2-Drive, a novel WMRL framework that integrates a high-fidelity world model with a multi-modal diffusion-based policy actor. It consists of two key components: DiffDreamer, a diffusion-based world model that generates future observations simultaneously, mitigating error accumulation, and DPA (Diffusion Policy Actor), a diffusion-based policy that models diverse and multi-modal trajectory distributions. By training DPA within DiffDreamer, our method enables robust policy learning with minimal online interactions. We evaluate our method in CARLA using standard driving benchmarks and demonstrate that it outperforms prior world model baselines, improving Route Completion and Success Rate by 15% and 20% respectively.
Imagine-2-Drive consists of a Diffusion Policy Actor (DPA) for trajectory prediction and DiffDreamer as a World Model for future state and reward prediction. (a) illustrates the overall pipeline: given the encoded state from the current and P past observations, DPA denoises a set of one-hot embeddings over K steps to generate H future discrete actions, forming the final denoised trajectory. This trajectory is further enriched using Fourier Embeddings and, along with past and current observations, is input to DiffDreamer to predict future H observations and rewards. (b) details DiffDreamer, comprising two components: SVD for future observation prediction and an additional head for reward prediction. In SVD, the first P noisy frames are replaced with past observations, while the current observation is repeated (P + H) times and concatenated with past and noisy frames for better grounding with the initial conditions.
Future obervation predictions from the DiffDreamer World Model, conditioned on the input trajectory and current observations. Demonstrates the DiffDreamer's ability to accurately predict future observations based on the provided context, highlighting its robust trajectory prediction capabilities.
@misc{garg2025imagine2driveleveraginghighfidelityworld,
title={Imagine-2-Drive: Leveraging High-Fidelity World Models via Multi-Modal Diffusion Policies},
author={Anant Garg and K Madhava Krishna},
year={2025},
eprint={2411.10171},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2411.10171}
}